(cluener 01)download_clue_data.py解读与重构
CLUENER2020/bilstm_crf_pytorch/download_clue_data.py在项目中所处位置如图:
CLUENER2020的download_clue_data.py里提供了数据下载脚本
""" Script for downloading all CLUE data.
For licence information, see the original dataset information links
available from: https://www.cluebenchmarks.com/
Example usage:
python download_clue_data.py --data_dir data --tasks all
"""
import os
import sys
import argparse
import urllib.request
import zipfile
TASKS = ["afqmc", "cmnli", "copa", "csl", "iflytek", "tnews", "wsc","cmrc","chid","drcd",'cluener']
TASK2PATH = {
"afqmc": "https://storage.googleapis.com/cluebenchmark/tasks/afqmc_public.zip",
"cmnli": "https://storage.googleapis.com/cluebenchmark/tasks/cmnli_public.zip",
"copa": "https://storage.googleapis.com/cluebenchmark/tasks/copa_public.zip",
"csl": "https://storage.googleapis.com/cluebenchmark/tasks/csl_public.zip",
"iflytek": "https://storage.googleapis.com/cluebenchmark/tasks/iflytek_public.zip",
"tnews": "https://storage.googleapis.com/cluebenchmark/tasks/tnews_public.zip",
"wsc": "https://storage.googleapis.com/cluebenchmark/tasks/wsc_public.zip",
'cmrc': "https://storage.googleapis.com/cluebenchmark/tasks/cmrc2018_public.zip",
"chid": "https://storage.googleapis.com/cluebenchmark/tasks/chid_public.zip",
"drcd": "https://storage.googleapis.com/cluebenchmark/tasks/drcd_public.zip",
'cluener':'https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip'
}
def download_and_extract(task, data_dir):
print("Downloading and extracting %s..." % task)
if not os.path.isdir(data_dir):
os.mkdir(data_dir) # 如果下载数据目录不存在,则建立一级目录'./dataset'
data_file = os.path.join(data_dir, "%s_public.zip" % task) # data_file = './dataset/task任务名_public.zip'
save_dir = os.path.join(data_dir,task) # 下载目录为'./dataset/task任务名'
if not os.path.isdir(save_dir):
os.mkdir(save_dir) # 如果下载目录不存在则建立下载目录
urllib.request.urlretrieve(TASK2PATH[task], data_file) # URL从指定链接下载文件到'./dataset/task任务名_public.zip'
with zipfile.ZipFile(data_file) as zip_ref:
zip_ref.extractall(save_dir) # 将'./dataset/task任务名_public.zip'解压到'./dataset/task任务名'
os.remove(data_file) # 删除'./dataset/task任务名_public.zip'
print(f"\tCompleted! Downloaded {task} data to directory {save_dir}")
def get_tasks(task_names):
task_names = task_names.split(",") # 分割多个下载目标
if "all" in task_names:
tasks = TASKS # 如果tasks=all的话,下载任务为十一个任务全部
else:
tasks = []
for task_name in task_names:
assert task_name in TASKS, "Task %s not found!" % task_name
tasks.append(task_name)
return tasks # 验证下载目标是否在给定列表中,并添加到tasks任务列表
def main(arguments):
parser = argparse.ArgumentParser()
parser.add_argument(
"-d", "--data_dir", help="directory to save data to", type=str, default="../CLUEdatasets"
) # data_dir为下载目录
parser.add_argument(
"-t",
"--tasks",
help="tasks to download data for as a comma separated string",
type=str,
default="all",
) # tasks可以给定all、单个、或者多个,多个以逗号分隔
args = parser.parse_args(arguments)
if not os.path.exists(args.data_dir):
os.mkdir(args.data_dir) # 如果 './dataset'不存在,则创建一级目录
tasks = get_tasks(args.tasks)
for task in tasks: # 遍历tasks中每个任务
download_and_extract(task, args.data_dir)
if __name__ == "__main__":
sys.exit(main(sys.argv[1:]))在训练模型之前需要将数据下载完毕,使用命令如下
python download_clue_data.py --data_dir=./dataset --tasks=cluener脚本整体仍是调用os和sys库完成,并且整体代码风格与模型主文件相比较为割裂,所以使用pathlib.Path重构该部分代码
'''
1. 验证data_dir目录是否存在,如不存在则建立一级目录
2. 对tasks进行划分,先验证是否为all,再依次验证划分出的各元素并添加列表
3. 再次验证data_dir一级目录是否存在,添加压缩文件路径和解压路径,验证解压路径是否为目录
4. 下载压缩文件,解压至解压路径,后删除压缩文件
'''
import argparse
from pathlib import Path
import urllib.request
import zipfile
# if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-data-dir', type=str, default='./dataset')
parser.add_argument('--tasks', type=str, default='cluener')
args = parser.parse_args()
TASKS = ["afqmc", "cmnli", "copa", "csl", "iflytek", "tnews", "wsc", "cmrc", "chid", "drcd", 'cluener']
TASK2PATH = {
"afqmc": "https://storage.googleapis.com/cluebenchmark/tasks/afqmc_public.zip",
"cmnli": "https://storage.googleapis.com/cluebenchmark/tasks/cmnli_public.zip",
"copa": "https://storage.googleapis.com/cluebenchmark/tasks/copa_public.zip",
"csl": "https://storage.googleapis.com/cluebenchmark/tasks/csl_public.zip",
"iflytek": "https://storage.googleapis.com/cluebenchmark/tasks/iflytek_public.zip",
"tnews": "https://storage.googleapis.com/cluebenchmark/tasks/tnews_public.zip",
"wsc": "https://storage.googleapis.com/cluebenchmark/tasks/wsc_public.zip",
'cmrc': "https://storage.googleapis.com/cluebenchmark/tasks/cmrc2018_public.zip",
"chid": "https://storage.googleapis.com/cluebenchmark/tasks/chid_public.zip",
"drcd": "https://storage.googleapis.com/cluebenchmark/tasks/drcd_public.zip",
'cluener': 'https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip'
}
if not Path(args.data_dir).exists():
Path(args.data_dir).mkdir(parents=True)
def get_tasks(task_names):
task_names = task_names.split(",")
if "all" in task_names:
tasks = TASKS
else:
tasks = []
for task_name in task_names:
assert task_name in TASKS, f"Task {task_name} not in TASKS!"
tasks.append(task_name)
return tasks
tasks = get_tasks(args.tasks)
def download_and_extract(task, data_dir):
print("Downloading and extracting %s..." % task)
if not Path(data_dir).exists():
Path(data_dir).mkdir(parents=True)
data_file = Path(data_dir) / f'{task}_public.zip'
save_path = Path(data_dir) / f'{task}'
if not save_path.exists():
save_path.mkdir() # 明显的一级目录,不赋予创立多级目录的权限
urllib.request.urlretrieve(TASK2PATH[task], data_file)
with zipfile.ZipFile(data_file) as zip_ref:
zip_ref.extractall(save_path)
data_file.unlink()
print(f"\tCompleted! Downloaded {task} data to directory {save_path}")
for task in tasks:
download_and_extract(task, args.data_dir)其中重点库的使用说明:
urllib.request 可以模拟浏览器的一个请求发起过程
其中,
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)将URL表示的网络对象复制到本地文件。如果URL指向本地文件,则对象不会被复制,除非提供文件名。
- url:外部或本地url。
- filename:指定保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据)。
- reporthook:回调函数,可以显示当前下载进度。
- data:指post到服务器的数据,该方法返回一个包含 (filename, header) 的元祖,其中header表示服务器响应头。
zipfile 支持zip格式压缩文件的操作,包括文件压缩、解压缩、查看压缩文件信息等,虽然支持加密文件的解密但不支持文件加密
其中,
zipfile.ZipFile(file, mode='r', compression=ZIP_STORED, allowZip64=True, compresslevel=None)
- file为指向文件的路径(字符串),一个类文件对象(path-like object)。
- mode='r' 表示读取已存在的一个zip文件(读取文件名即file);
- mode='w'表示新建一个zip文件或覆盖一个已存在的zip文件(新建/覆盖文件名即file);
- mode='x'表示仅新建一个zip文件,如果file指向已存在文件则报错(新建文件名即file);
- mode='a'表示如果file文件不存在则新建,如果file文件已存在,则将数据附加到file文件中(新建/追加文件名即file)。
- compression是写入归档时要使用的zip压缩方法。
- allowZip64默认为True,表示当zipfile大于4GB时将创建使用ZIP64扩展的zip文件,此时如果为false则报错。
compresslevel表示将文件写入归档时要使用的压缩等级。
- 压缩
with zipfile.ZipFile('zipname.zip', 'w') as zipname: # 新建或覆盖zipname.zip,并用zipname表示
zipname.write(path) # 将path指向的文件写入zipname.zip
zipname.close() # 关闭压缩文件- 解压缩
with zipfile.ZipFile('zipname.zip', 'r') as zipname: # 读取zipname.zip,且用zipname表示
zipname.extractall(path) # 解压zipname.zip内部所有文件到特定目录path
zipname.close()- pathlib.Path.unlink(),即表示删除Path指向的文件。
download_clue_data.py作用效果如下: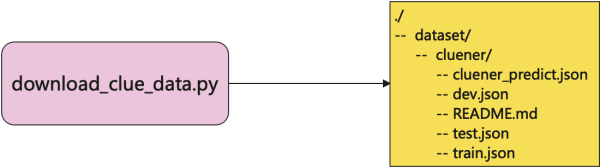
评论已关闭