(cluener 00)README
大概在去年十月份,阅读了NER项目 [targer]: https://github.com/achernodub/targer 的代码,除模型架构外大多是在函数作用层面了解项目构造。最为重大的收获便是学习了如何将项目写的更具结构化,包括收获到一些封装和引用的技巧。虽然多层的封装最开始对我的阅读造成了很大影响,不过在足够的锻炼之后,我才发现再拿到一个新项目时阅读代码能力有显著的提升。非常的感谢这个项目。
在梳理和学习这个项目后,我主要做的是模仿。将从这个项目中学习到的项目化逻辑应用到textcnn、textrnn等nlp-toys中,当时差不多每天抽出一些时间完成一个模型的项目化封装后便上传github,也导致了很久的博客拖更。
CLUENER2020这个项目 [CLUENER2020]: https://github.com/CLUEbenchmark/CLUENER2020 之所以让我下定决心从更细粒度学习是因为,好吧,其实是因为我在cluener2020数据集上也使用复现的模型和其他人复现的模型都不能取得那么好的效果,所以决心要比targer更细粒度的拆解下。主要的阅读思路应该会延续从main.py文件逐句阅读的模式,一般重点的知识点会说明下,并且尝试重构下项目使得更有个人的特色(并不说明会比原项目好),仅供学习。
附个人总结targer项目结构图: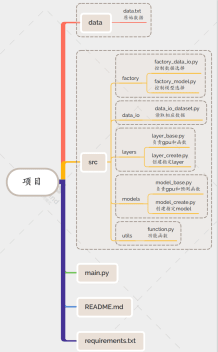
评论已关闭